Back in January, flaky tests were a serious problem for Servo’s development. Each build failure caused by flaky tests would delay merging a pull request by over two hours, and some changes took as many as seven tries to merge! But since then, we’ve made a bunch of improvements to how we run tests, which should make contributing to Servo a lot easier.
What is a flaky test?
Servo is tested against the Web Platform Tests, a suite of over 30,000 tests shared with all of the major web engines. Each test can pass, fail, crash, or time out, and if a test has subtests, each subtest can have its own result. Passing is not always the expected outcome: for example, we would expect most tests for unimplemented features to fail.
Flaky tests are tests that yield the expected outcome sometimes and an unexpected outcome other times, causing intermittent build failures. Tests can be flaky due to how they were written, or problems with the machines that run those tests, but often they flake due to Servo bugs. Regardless of the cause, we want to avoid letting flaky tests affect people doing unrelated work.
Faster build times
Making builds faster doesn’t directly make tests less flaky, but it does reduce the delays that flaky tests can cause.
Our main try and merge builds often took three or four hours to complete, because our GitHub org was limited to 20 concurrent runners. Since we also split the Web Platform Tests into 20 concurrent jobs, some of those jobs would almost always get starved by other jobs, like Windows unit tests or nightly WPT updates.
We reached out to GitHub about this, and they were kind enough to increase our free runner limit to 60 concurrent jobs, cutting our build times to a consistent two hours.
In the future, it may be worth adding some caching of the Cargo and target directories across builds, but the slowest parts of our builds by far are the Windows and macOS jobs. While neither of them run the Web Platform Tests yet, even just compiling and running unit tests takes over 90 minutes, making them almost always the critical path.
We are hoping this will improve with initiatives like GitHub’s upcoming “XL” macOS runners, and in the longer term it may be worth setting up some dedicated runners of our own.
Support for multiple expectations
We were previously only able to handle flaky tests by marking them as intermittent, that is, creating an issue with the test name in the title and the label I-intermittent. This means we treat any result as expected when deciding whether or not the build should succeed, which is a very coarse approach, and it means the list of intermittent tests isn’t version controlled.
But as of #29339, we can now give tests a set of expected outcomes in the metadata files! Note that the typical outcome, if any, should go first, but the order doesn’t really matter in practice.
# tests/wpt/metadata/path/to/test.html.ini
[test.html]
[subtest that only fails]
expected: FAIL
[subtest that occasionally times out]
expected: [PASS, TIMEOUT]
In the future, it may be worth migrating the existing intermittent issues to expectations like this.
Retrying tests with unexpected results
Sometimes the causes of flakiness can affect many or even all tests, like bugs causing some reftest screenshots to be completely white, or overloaded test runners causing some tests to time out.
Thanks to #29370, we now retry tests that yield unexpected results. If a test yields the expected result on the second try, we ignore it when deciding whether or not the build should succeed. This can make builds a little slower, but it should be outweighed by our recent improvements to build times.
In the future, it may be worth adopting some more advanced retry techniques. For example, Chromium’s retry strategy includes retrying the entire “shard” of tests to reproduce the test environment more accurately, and retrying tests both with and without the pull request to help “exonerate” the changes. These techniques require considerably more resources though, and they are generally only viable if we can fund our own dedicated test runners.
Result comments
As of #29315, when a try or merge build finishes, we now post a comment on the pull request with a clear breakdown of the unexpected results:
- Flaky unexpected results are those that were unexpected at first, but expected on retry
- Stable unexpected results that are known to be intermittent are those that were unexpected, but ignored due to being marked as intermittent
- Stable unexpected results are those that caused the build to fail
Intermittent dashboard
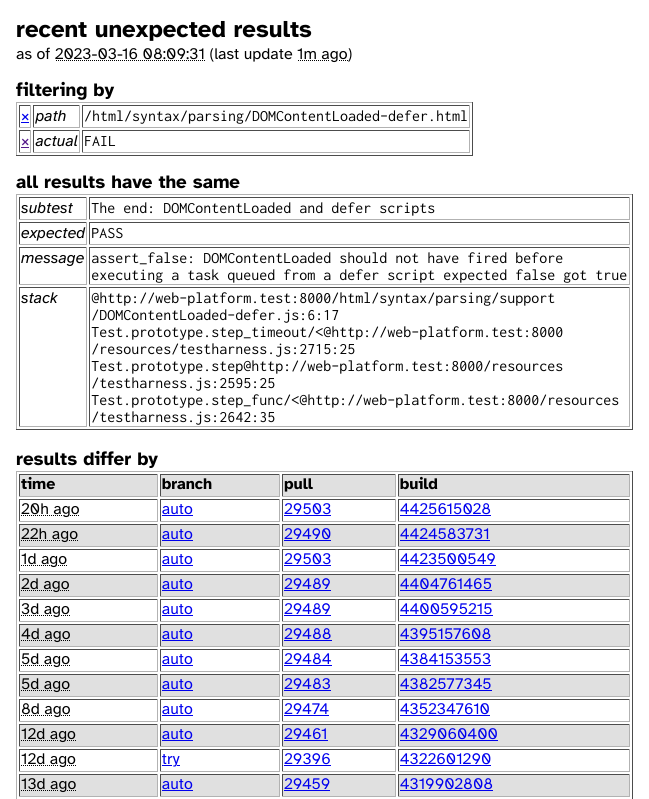
To ensure that flaky tests can be discovered and fixed even if they are mitigated by retries, we’ve created an intermittent dashboard that all unexpected results get reported to.
Each result includes the test and subtest, the expected and actual outcomes, any test output, plus metadata like the commit and a link to the build. You can filter the data to a specific test or field value, and the dashboard automatically points out when all of the visible results have something in common, which can help us analyse the failures and identify patterns.
For example, here we can see that all of the unexpected failures for one of the HTML parsing tests have the same assertion failure on the same subtest, but are not limited to one pull request:
In the future, we plan to further develop the dashboard, including adding more interesting views of the data like:
- which tests flake the most (within some recent period like 30 days)
- which tests are starting to flake (newly seen or quickly spiking)
- which tests are marked as intermittent but haven’t flaked recently